Real-Time Collaborative Robot Handling
Rui Chen*, Alvin Shek*, Changliu Liu
Submitted to IEEE Transactions on Robotics (T-RO) 2022
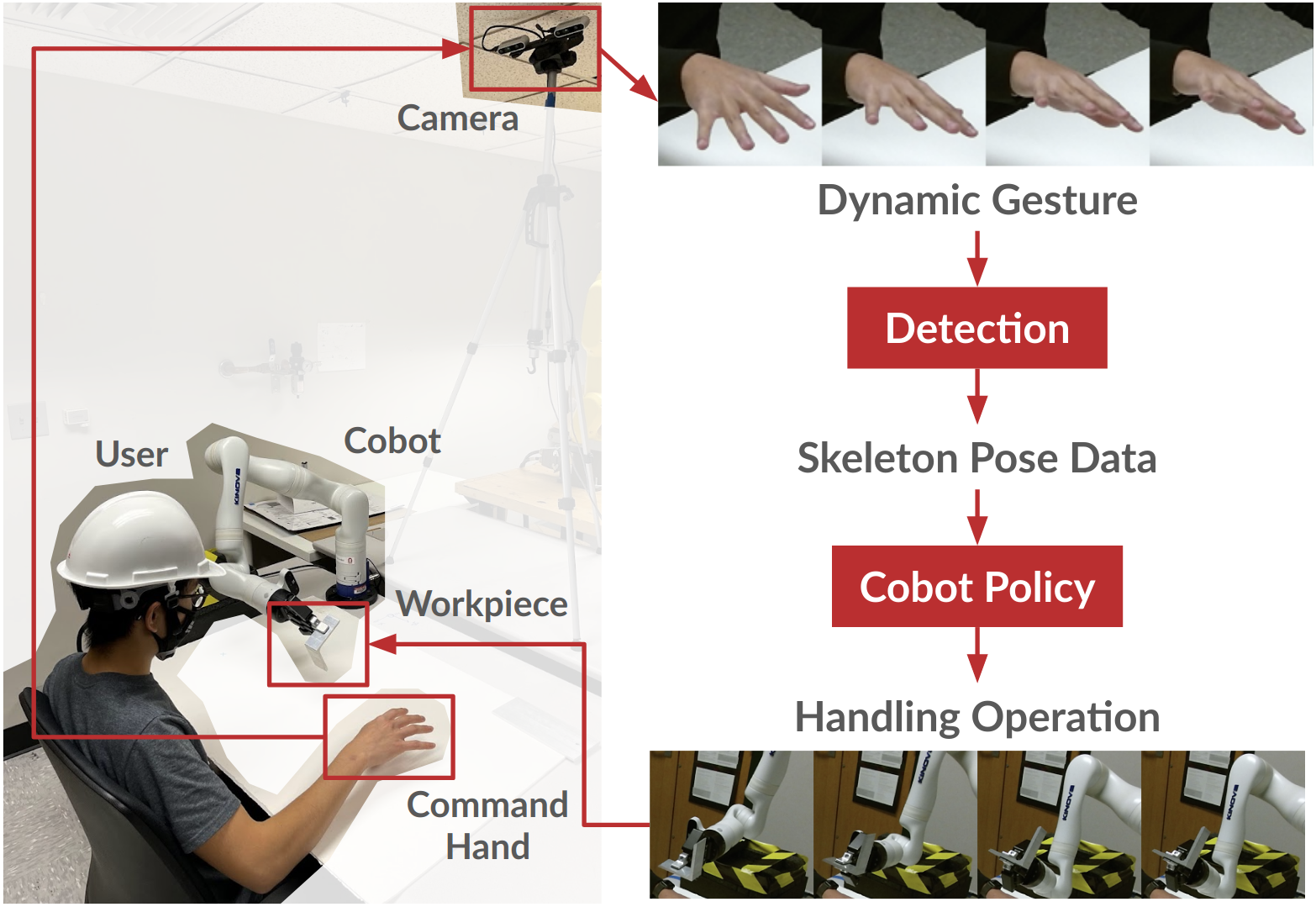
Intro
With the advancement of robotic technologies, robots are getting out of cages and directly working with humans. One immediate application of collaborative robot (cobot) is material handling where the robot moves or presents a workpiece under human commands in real time. It is particularly useful when the material to handle is heavy, as in automotive assembly, or when the material needs to stay untouched by human, as in the case of food production, or when there are safety risks, as in the case of dangerous liquid.
Existing interfaces with robots such as keyboards and joysticks require either tedious integration efforts or programming expertise and can hardly be used in real- time. Other interfaces such as voice or static hand gestures are more user intuitive and require no technical skills to be learned beforehand. Static gestures, however, are limited to generating discrete motion primitives rather than real-time, continuous movements and thus limit the flexibility of robot behavior. Our approach is unique in this aspect by handling continuous, dynamic gestures.
Framework
The above video shows me demonstrating the final performance of our model. As I perform various hand motions that involve multiple Cartesian dimesnsions at the same time (ex: translating from left to right while rotating), we see that the model is able to interpret this correctly and infer the correct robot motion. Specfically, our model takes as input 6D translational and rotational velocities of each finger and palm of the right hand, which we calculate from OpenPose finger keypoint positions. Our model then outputs 6D translational and rotational velocities of the robot end-effector.
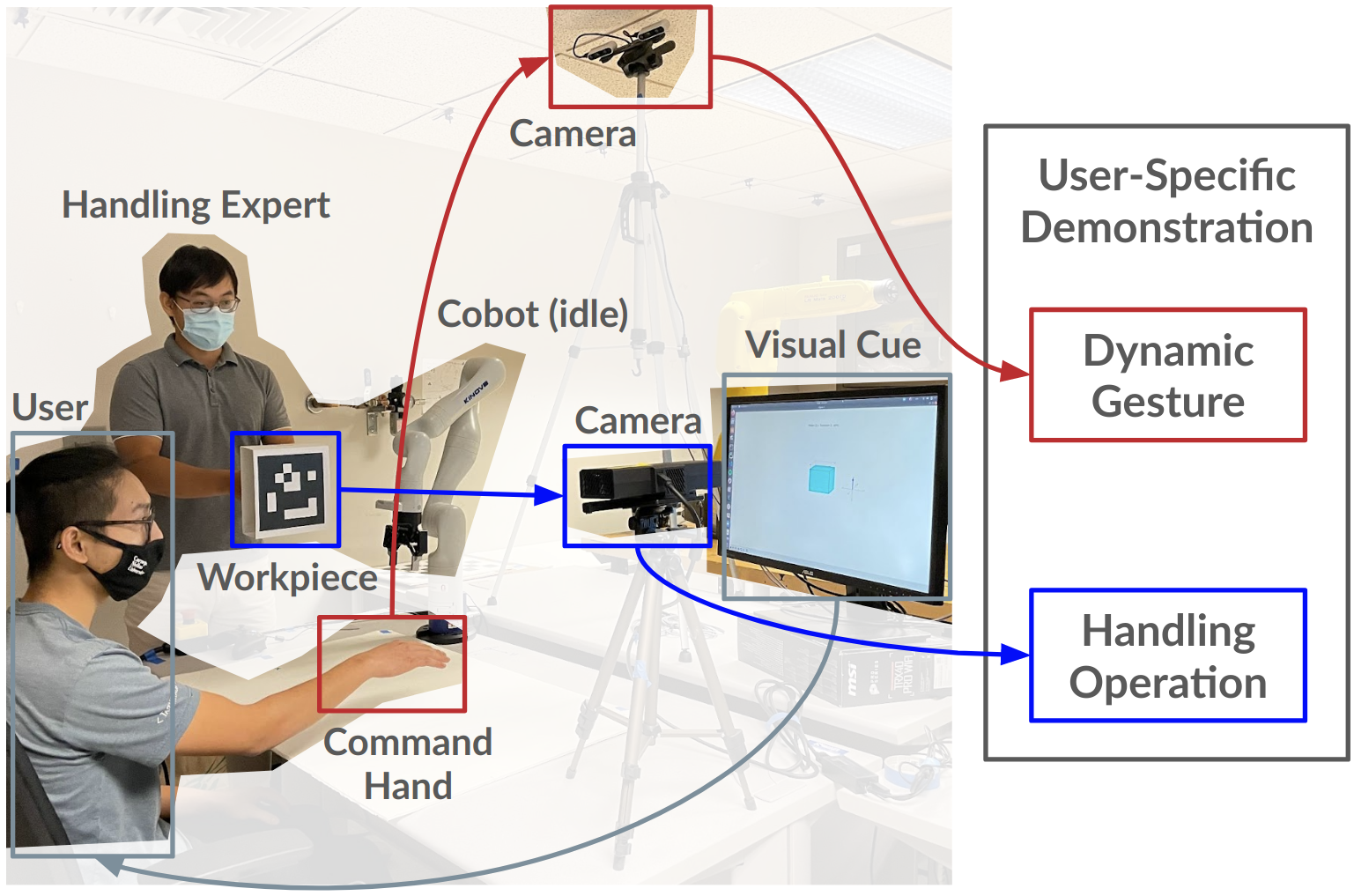
To train this model, we collected data from a series of human-human collaboration trials. One user would watch an animation of the desired motion of a box and would try generating the hand motion to match this. A second user would interpret the first user's hand motions and move a real, physical box whose 6D pose would be tracked. As a result, we would obtain both the hand motion input to the model as well as the ground truth object motion representing the robot end effector.
Probabilistic Formulation: Generative Process
There are several key challenges in interpreting human commands. First, people think and act differently, and this can cause different users' hand motion styles to vary drastically. Machine Learning models expect inputs to come from a distribution that matches what was seen at training. The diversity in user styles means that a new user's style may not have been seen at training, which can cause unpredictable model outputs. To handle this diversity, we draw inspiration from Attentive Neural Processes by training our model to condition on some prior "context" or calibration data collected by previous users. The idea is that the model can reference previously seen data to help it interpret new user data. This is done through an attention mechanism over LSTM hidden states that capture latent features of a time series of both hand and desired object motion. Please see the "Encoder Cell" under Section V.A of our paper for more details.
Another challenge is in modeling human motion uncertainty. Given the exact same desired object motion, a human may execute different hand motions in different trials. Our model needs to handle this stochasticity in the expert demonstration. We formulate our problem as a generative process with the goal of maximizing the expected log-probability of the ground truth object motion when conditioned on the input hand motion. Please see Eqn. 4 in our paper for details.
A final challenge is that our robot will operate in close proximity to humans. From a human perspective, it is easy to predict the behavior of smooth motions but not sharp, sudden motions. As a result, we need our learned robot policy to also output smooth, continuous motions. We achieve this by formulating our generative process to condition also on the previous model output. This way, our model's future output is dependent on its previous output. We train this dependency using Teacher Forcing.
Conclusion
This project helped me realize the many challenges of interacting with humans that collaborative robots must address. Many more issues exist that were not covered in this project, and I am currently exploring these further as a part of my masters thesis.
Alvin Shek
Robotics Masters Student @ CMU
Robotics, Computer Vision, Deep Learning, Reinforcement Learning.