Summary
Motion Planning for mobile robots (ie: autonomous cars) often do not need to worry about the terrain: the road is reasonably paved and maps are accurate. However, when applying robotics to rough terrain, especially terrain that is not accurately mapped, a vehicle must be more careful about where it moves. Based on sensors, it needs to quickly update its prior knowledge about the surrounding terrain and update motion plans in real time to avoid risky terrain. This idea motivated me to study incremental search under mentorship of Dr. Qin Lin. Specifically, I explored the D* Lite algorithm and implemented the baseline algorithm on a 2D environment with simple car kinematics and not dynamics. Full details about implementation (state and action space, heuristic, datastructures, etc...) can be found in this document.
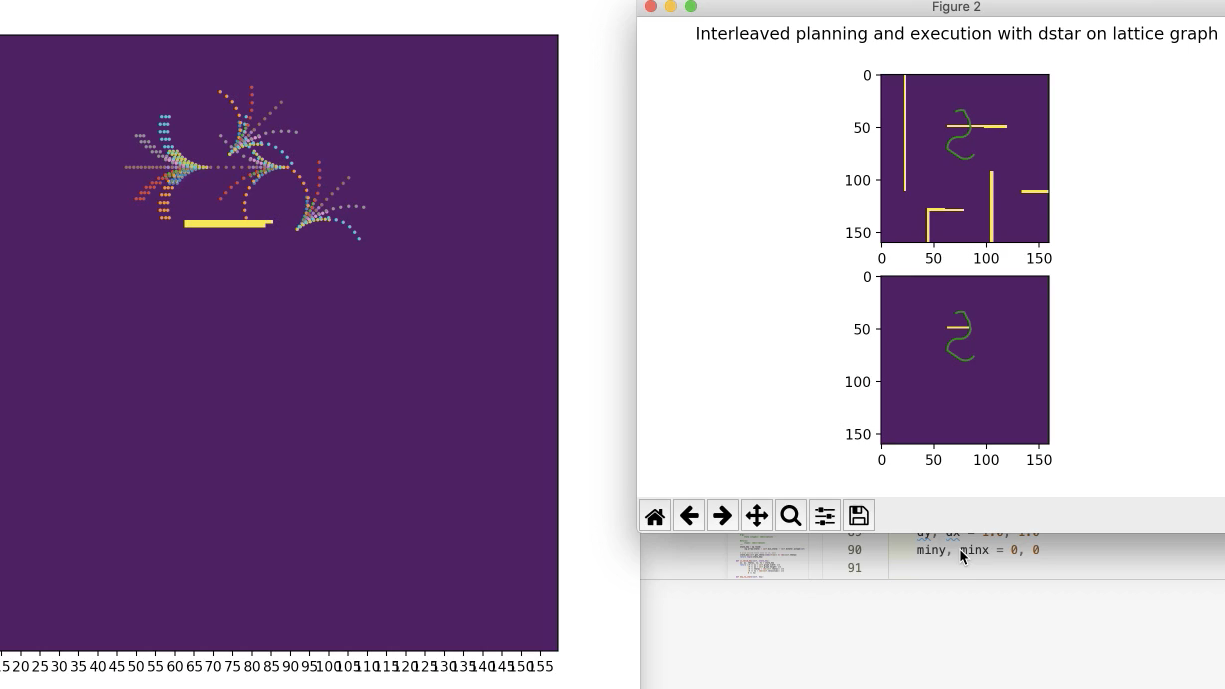
A full video of the planner (though still contains a bug as you can see at the end) is shown below. The graph on the right displays newly-expanded states (and all the actions/rollouts stemming from that state). The graph on the top right shows the robot's current plan on the true map (which is not fully known). The bottom right shows the plan on the map known to the robot. You can see that the planner will update its plan as it updates its known map.
In basic maze-finding, an action is to simply move up, down, left, or right. For a kinematic vehicle, however, we can use motion primitives defined by velocity and steering angle to precompute rollouts. Then based on the car's current position and orientation, we simply apply 3D transform (translation + rotation) to the predifined motion swaths. Those are the colorful flower-looking shapes, each dot representing an intermediary state along that path.
Notice that initially, the planner must expand all necessary states to find a path from start to goal, hence identical to A* search:
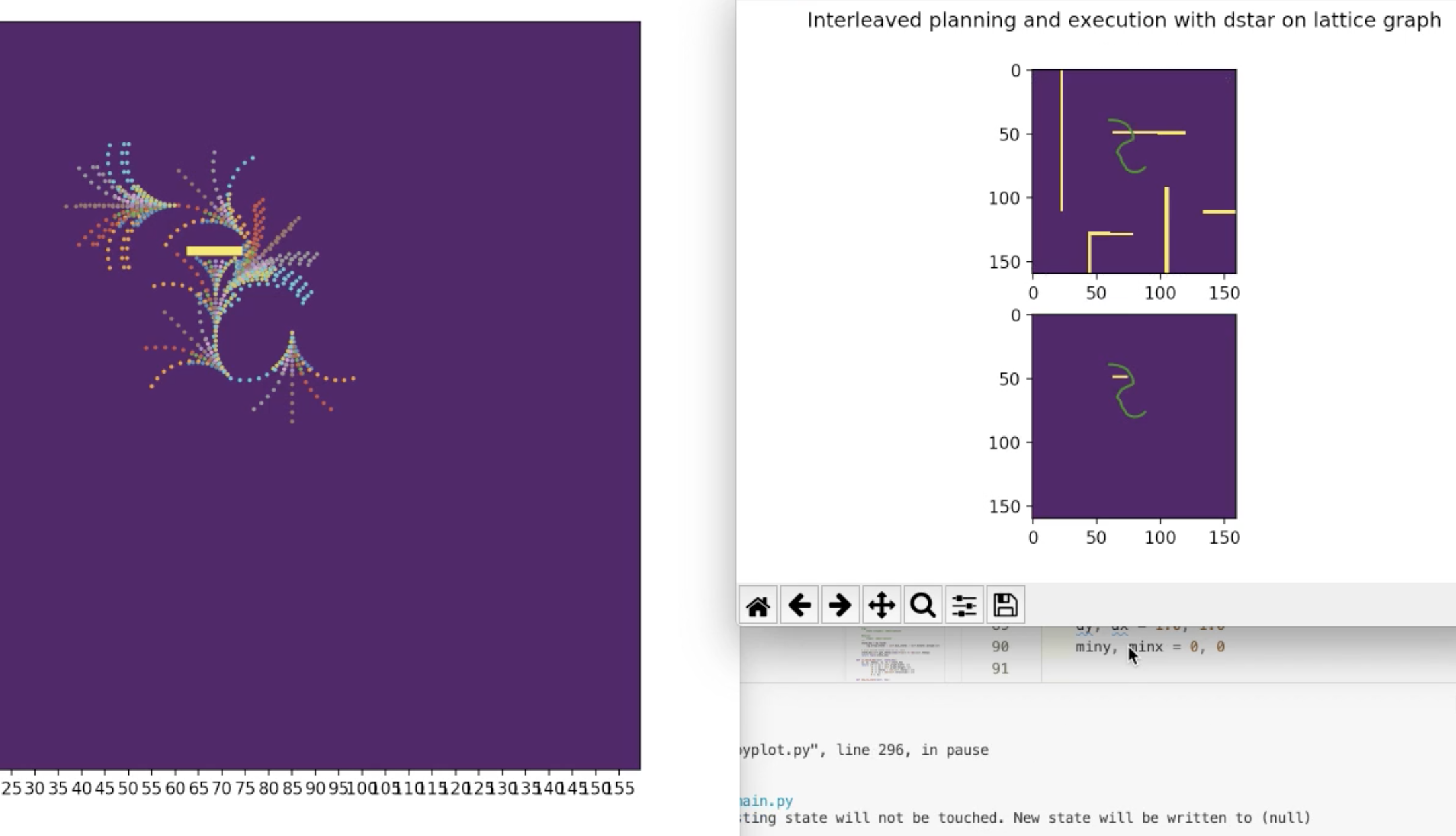
After this initial plan, the robot moves one step along the found path, rescans the environment and discovers some new sections of the yellow wall and needs to recalculate cost values for affected states. Those modified states are added back to the "open set", a priority queue for which states to explore sorted by lowest cost.
Thoughts
My implementation is actually not completely correct because I misunderstood this key line of the algorithm:

This one, subtle line: "scan graph for changes in edge costs" actually involves a lot of computation if the edge cost calculation is heavy. In our case, edge cost calculation is expensive since every state and rollout needs to be collision-checked and transition costs summed up. I never got around this major roadblock, and had time to only stick with my wrong implementation.
Alvin Shek
Robotics Masters Student @ CMU
Robotics, Computer Vision, Deep Learning, Reinforcement Learning.