For robots to be effectively deployed in novel environments and tasks, they must be able to understand the feedback expressed by humans during intervention. This can either correct undesirable behavior or indicate additional preferences. Existing methods either require repeated episodes of interactions or assume prior known reward features, which is data-inefficient and can hardly transfer to new tasks. We relax these assumptions by describing human tasks in terms of object-centric sub-tasks and interpreting physical interventions in relation to specific objects. Our method, Object Preference Adaptation (OPA), is composed of two key stages: 1) pre-training a base policy to produce a wide variety of behaviors, and 2) online-updating only certain weights in the model according to human feedback. The key to our fast, yet simple adaptation is that general interaction dynamics between agents and objects are fixed, and only object-specific preferences are updated. Our adaptation occurs online, requires only one human intervention (one-shot), and produces new behaviors never seen during training. Trained on cheap synthetic data instead of expensive human demonstrations, our policy demonstrates impressive adaptation to human perturbations on challenging, realistic tasks in our user study. More details provided in the paper.
Ablation Studies
Zero-shot Transfer to Different Environment Settings
A major advantage of defining our policy relative to objects and learning features for object-centric behavior is that our policy naturally handles different environment settings. This is crucial: robots should be flexible in their behavior when objects get shifted and rotated around. The video below shows an extension of task 3 from our paper that examines behavior of the policy as the scanner's pose changes. Given human correction in an initial setting A, the policy should still behave correctly in different settings B and C without the need for additional supervision (zero-shot).
"Singularities" of Potential Fields
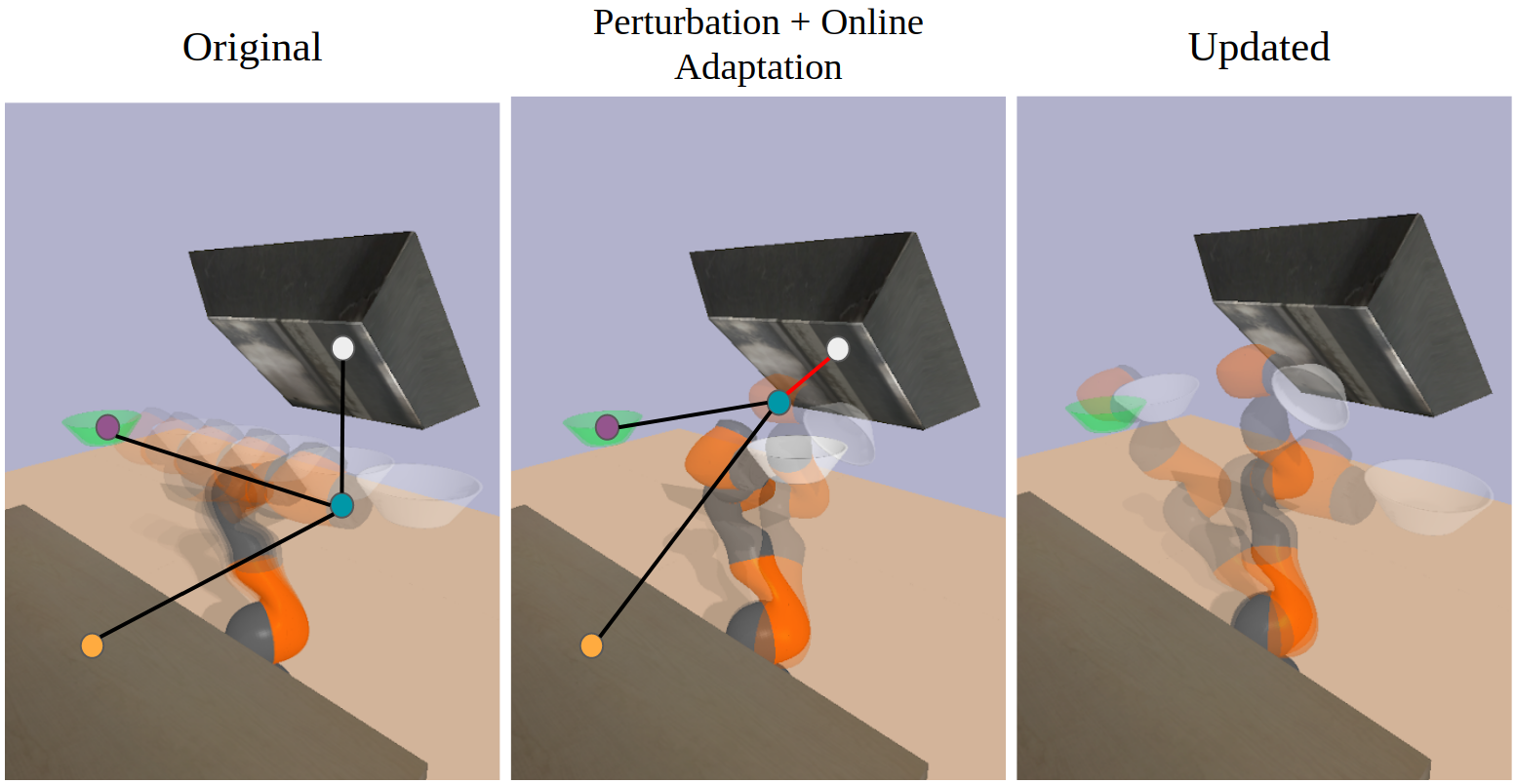
In Section 3-B of the paper, we mentioned how the position relation network overall outputs a push-pull force on the agent. We allow this direction to be freely determined by the network. Potential field methods also use this approach, but constrain the direction to be parallel to each agent-object vector. Only magnitude and sign of the vector can change. This may seem like an intuitive way to enforce structure in the network and reduce complexity, but this constraint fails during “singularities” where no orthogonal component is available to avoid an obstacle lying in the same direction as the goal.
Scalability with Objects
Graph-based models and neural networks have an advantage of being invariant to the order and number of objects in a scene. We only trained our model's position relation network in scenarios with two other objects: repel and attract. Ideally, our model should be able to generalize to more objects. Here, we examine this generalization ability. The below video shows our model on scenarios with 4 objects: two repel, two attract. The text at the center of each object displays the attention value placed on that object in the format att: value.
Tuning the Adaptation Learning Rate
Coming Soon: Comparison of Stochastc Gradient Descent vs Learned Optimizer (Learn2Learn) vs Recursive Least Squares