 High attention on black car
High attention on black car
Intro
In 2018, more than 4.4 million people were injured from car accidents. Predicting other accidents, even a few seconds before, can help drivers avoid adding to the damage. For our project, we would like to predict accidents a few seconds before they occur and provide some metric of uncertainty on nearby drivers. This will enable drivers to perform emergency, evasive actions just as the accidents happen rather than seconds later. Human drivers especially may not be able to tell that accidents will happen, so our system will assist them.
The original Anticipating Accidents in Dashcam Videos applies attention spatially across a single image, learning the weights to place on each vehicle feature vector in a scene. Attention locations are not determined by the prediction model. Rather, an upstream object detector detects vehicles (buses, cars, bikes, motorbikes) as well as people. It crops and feeds each object into a feature extractor. These features inherently represent various boxed regions in the original image, and as the model learns which features are important (order is important when fed in as a matrix), we can visualize this attention on each bounding box (main image above). The pipeline can be visualized below:
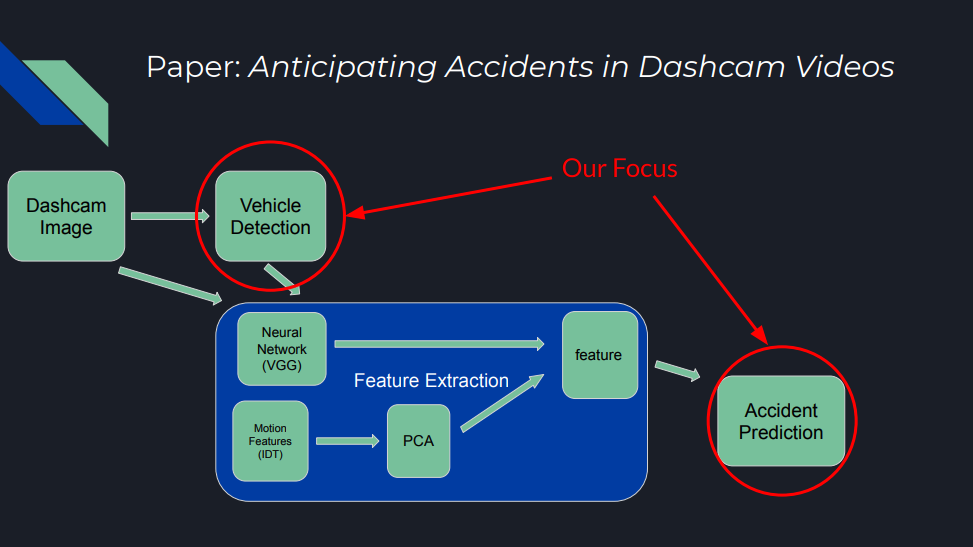 Full Pipeline
Full Pipeline
We decided to introduce a new modification: learn attention across time on the full image features. Our proposed model overall still retains the original paper’s spatial object attention, but now additionally learns which of the previous k image frames are most important for predicting an accident in the current frame. This idea drew inspiration from Listen, Attend, and Spell, whose model learns attention on audio samples across time to predict text. This can be summarized by the image below:
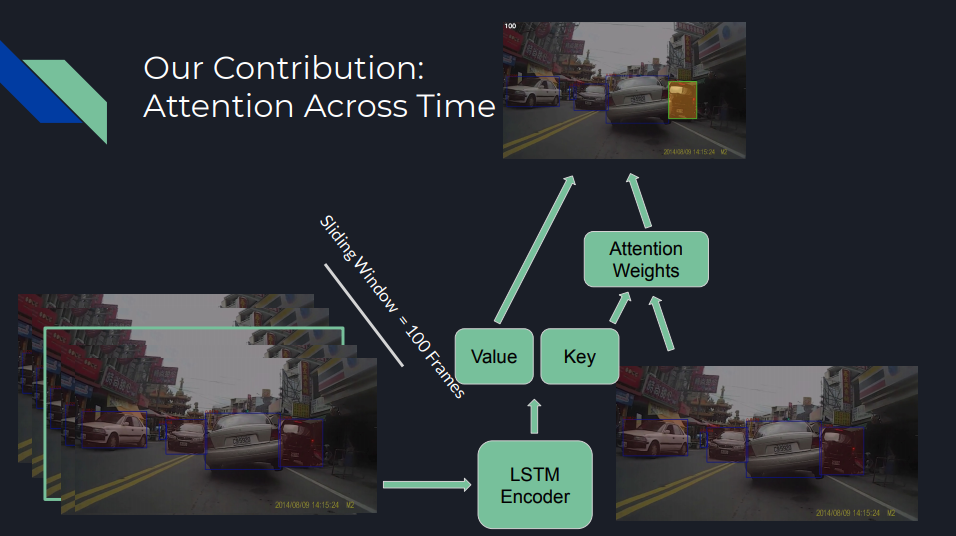
Results

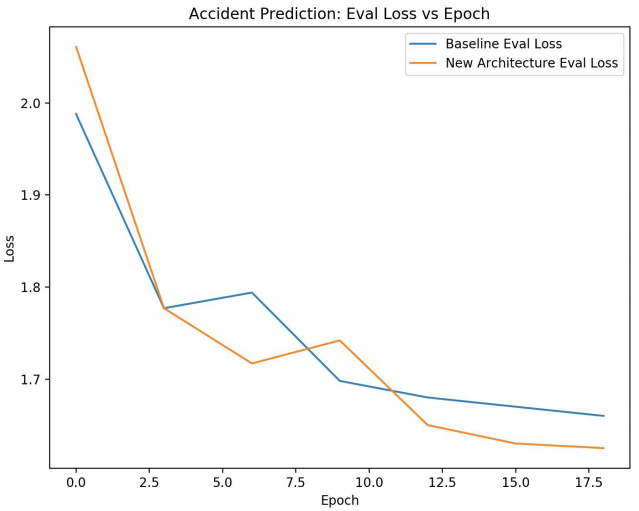
The figure on the left plots evaluation loss vs epoch. At the 18th epoch, we achieved an evaluation loss of 1.625 compared to the baseline model’s loss of 1.66.
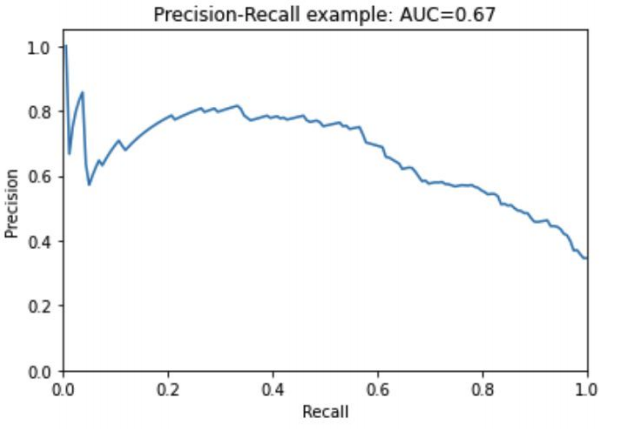
The figure on the right plots precision vs recall. One can interpret this by picking a desired level of recall (example 0.8) and seeing the corresponding precision. Maximizing both would be desirable. As a refresher, here are the definitions of precision and recall:
- Precision = True Positives / Predicted Positives
- Recall = True Positives / Actual Positives
Tools
- The original model was written in Tensorflow. For educational purposes, I reimplemented this in Pytorch.
Contribution
Looking at the pipeline image, I worked on improving accident prediction, while my teammates worked on improving vehicle detection.
Thoughts
This project was extremely rushed. For that reason, I admit that the results achieved here are not indicative of the true effectiveness of attention over time. Specifically, I examined the time attention plots and noticed in the final epochs that all attention was placed on the first timestep:
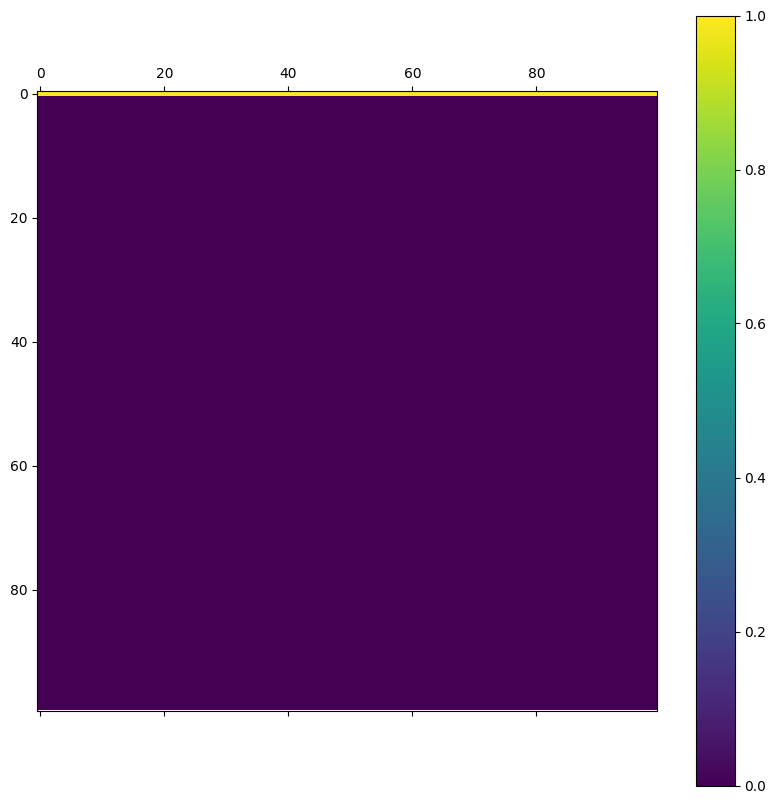 In hindsight, it honestly doesn't make much sense to place attention
across time. In speech-to-text, audio samples should be correlated in
time with the text generated. The audio samples of "Hello" should
correspond to "H", "e", "l", "l", "o" in this exact order, where audio
samples of "H" should be in the beginning of a recording. However, for
car accident prediction, different timesteps can contain useful
indications of accidents. In this case, we can't learn a standard rule
for attention to apply on all videos. The important timesteps for
accident prediction depend on the scenario. I realized this while
writing this blog post and will keep this lesson in mind when working
with attention mechanisms in the future.
In hindsight, it honestly doesn't make much sense to place attention
across time. In speech-to-text, audio samples should be correlated in
time with the text generated. The audio samples of "Hello" should
correspond to "H", "e", "l", "l", "o" in this exact order, where audio
samples of "H" should be in the beginning of a recording. However, for
car accident prediction, different timesteps can contain useful
indications of accidents. In this case, we can't learn a standard rule
for attention to apply on all videos. The important timesteps for
accident prediction depend on the scenario. I realized this while
writing this blog post and will keep this lesson in mind when working
with attention mechanisms in the future.
Alvin Shek
Robotics Masters Student @ CMU
Robotics, Computer Vision, Deep Learning, Reinforcement Learning.